One framework to rule them all?
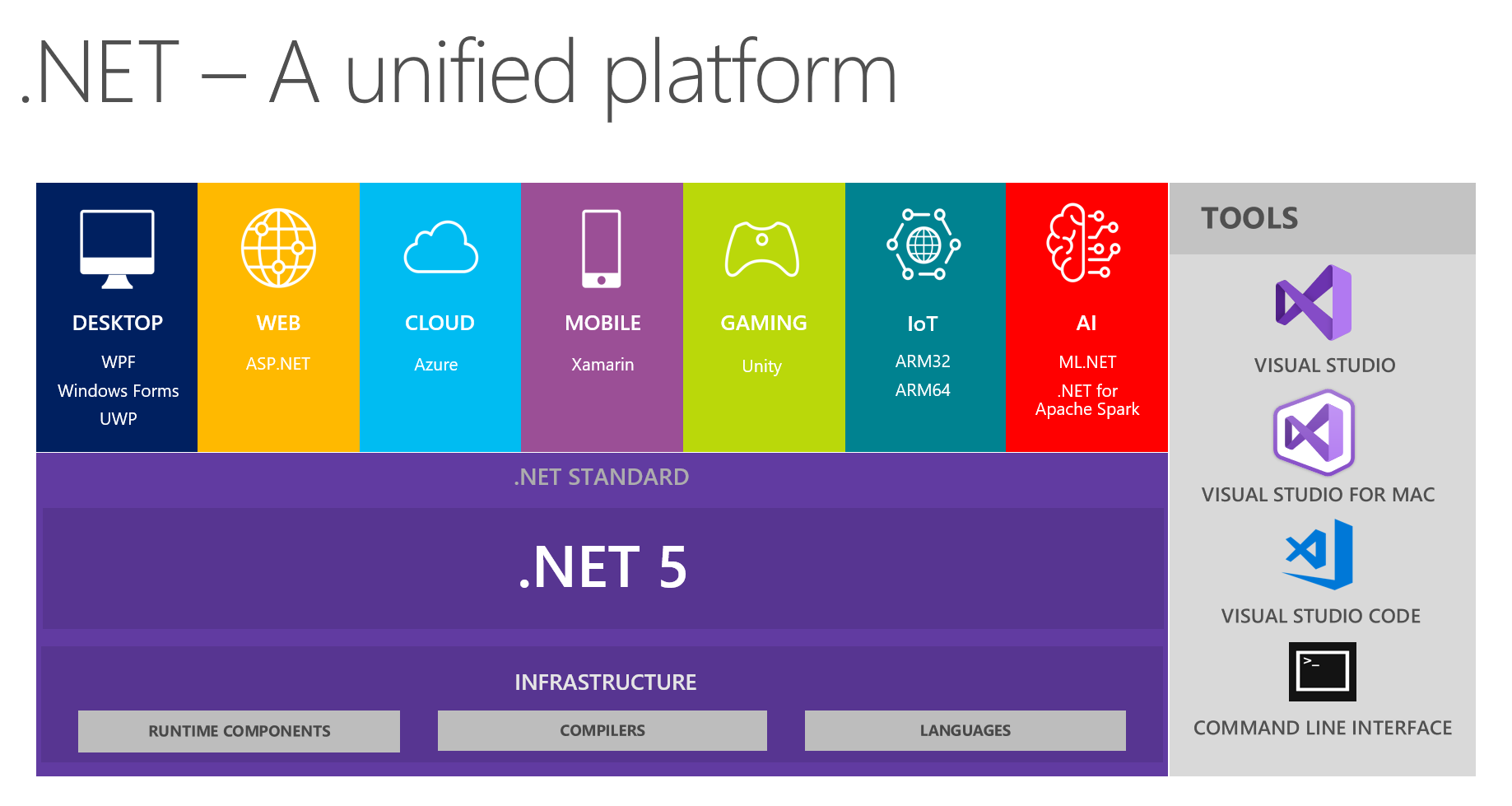
.NET 5 is on the way and scheduled to be delivered in November 2020. It is meant to unify .NET Framework, .NET Core, Mono (and possibly .NET Standard) - i.e. the entire .NET Platform.
After 17 years of working in .NET (since it was first released in 2002), I'm excited to see a unified solution to the splintered framework that .NET has become as of late. IMO, .NET Framework, .NET Core, .NET Standard, and Mono have grown into a big bad monster that is growing faster than its parts can manage. While we know (and expect) technology to evolve and grow over time, we hope that it doesn't fragment and splinter so much that its parts become dissimilar. I've seen it grow from a set of APIs that were questionable to something that is almost overwhelming - and certainly difficult to keep up with. I'm pleased to see that Microsoft has acknowledged the splintering and has been working on a solution since at least December 2018. I'm looking forward to seeing how much simpler things will become.
Now if they could just FINALLY fix "Edit and Continue"...........
(image is copyright of Microsoft)